

macOS、Windows、Linux、Docker等各个平台通过ollama一键部署谷歌最新开源的gemma大模型,免费开源离线部署使用超越llama2、chatgpt4
macOS、Windows、Linux、Docker等各个平台通过ollama一键部署谷歌最新开源的gemma大模型,免费开源离线部署使用超越chatgpt4。谷歌最强开源大模型亮相!Gemini技术下放,笔记本就能跑,可商用。

谷歌12天连放三个大招
9日-宣布其最强大模型Gemini Ultra免费用,于2023年12月发布时在MMLU(大规模多任务语言理解)测评上超过人类专家,在32个多模态基准中取得30个SOTA(当前最优效果),几乎全方位超越GPT-4,向OpenAI发起强势一击。
16日-放出大模型“核弹”Gemini 1.5,并将上下文窗口长度扩展到100万个tokens。Gemini 1.5 Pro可一次处理1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库,向OpenAI还没发布的GPT-5发起挑战。
21日-突然放出开源模型Gemma,谷歌在被“抢头条”后,一举将采用与Gemini相同研究和技术的Gemma开源,一是狙击Llama 2等开源模型,二是为生成式AI的应用开发者带来福音。
谷歌这动作之密集、行动之迅速,似乎在向抢了自己风头的OpenAI宣战。

一夜之间,Gemma系列正式上线,全面对外开放。
它采用Gemini同款技术架构,主打开源和轻量级,免费可用、模型权重开源、允许商用,同时笔记本可跑。
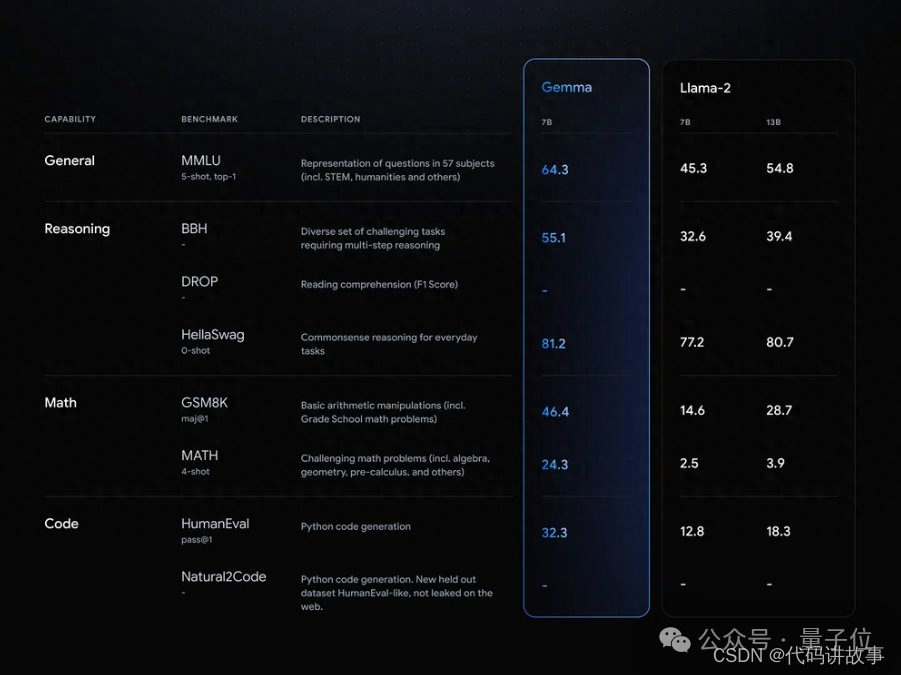
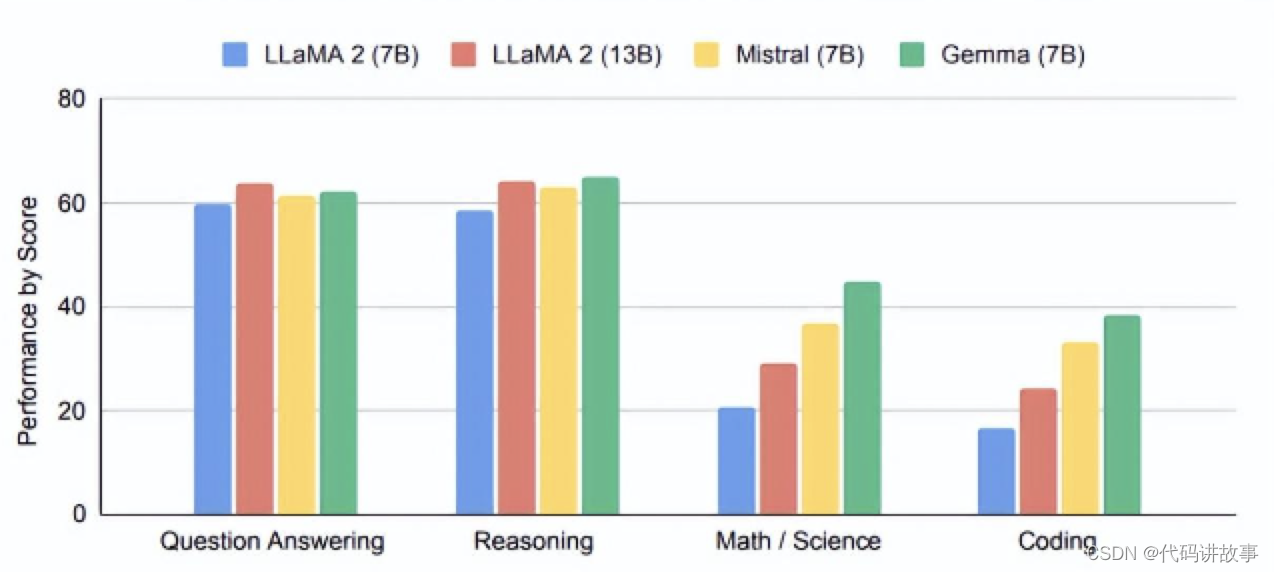
共有2B和7B两个版本,性能全面超越开源标杆Llama 2。
每种规模都有预训练和指令微调版本,可在Kaggle、Colab Notebook、Google Cloud中访问。
而且支持JAX、PyTorch和TensorFlow通过原生Keras 3.0进行推理和监督式微调(SFT),适应多种开发需求和环境。得益于对JAX的支持,它还能进行快速推理。
目前模型也同步上线Hugging Chat,可在线体验试玩。
发布几个小时里,Gemma火速成为圈内最热话题,成为议论焦点。
多性能超越同规模开源模型
具体来看Gemma的技术报告。
在18个任务中,Gemma在11个任务上表现优于同规模优质开源模型。
Gemma包含两种规格。
7B版本参数量约78亿,面向GPU和TPU上的高效部署和开发,2B版本参数量约25亿,用于CPU和端侧应用程序。
它基于Transformer解码器架构,关键模型参数如下。

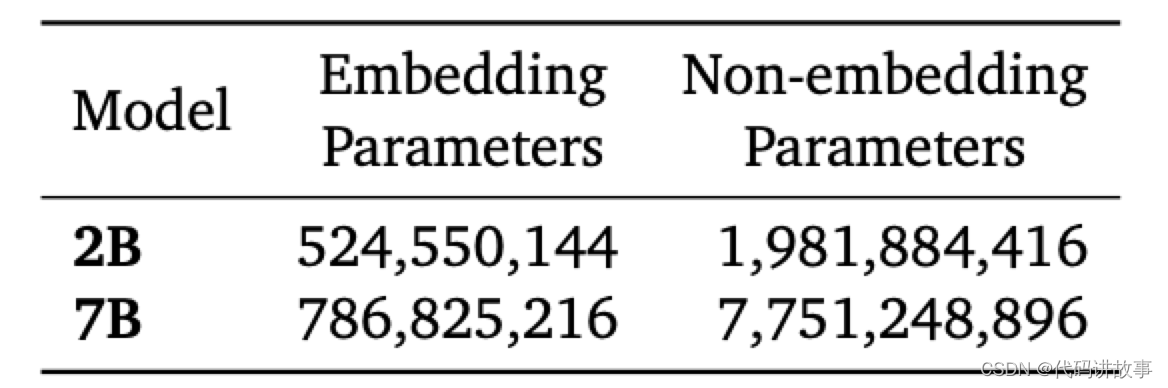
相比于基础Transformer,Gemma进行了一些升级。
7B版本使用多头注意力机制,2B版本使用多查询注意力机制。
在每一层中使用旋转位置嵌入代替绝对位置嵌入;使用GeGLU激活函数替代标准ReLU非线性。
同时对每一个子层的输入和输出都进行归一化。
Gemma 2B/7B分别使用了2T和6T token进行训练,主要来自网络文档、数学和代码,不过这些数据不是多模态的。
为了兼容,谷歌使用了Gemini的SentencePiece tokenizer子集,它可以分割数字,不删除额外的空格,并对未知token进行字节级编码。
大神卡帕西关注了Tokenizer部分,他表示,Gemma的tokenizer和Llama 2的不同,但和GPT一致。
François Chollet认为Gemma最大的特点是谷歌拥有SOTA级测试集过滤机制,这意味着基准数据能相当准确地反映了模型在实际环境中的表现。
谷歌也报告了Gemma在MMLU等基准上的表现。
最后,谷歌还强调了Gemma的安全隐私性能。
实验数据显示Gemma不会存储敏感数据,但可能会记住一些潜在隐私数据。不过报告表示这个数据可能因为工具原因有所误报。
gemma:https://ollama.com/library/gemma
Gemma is a family of lightweight, state-of-the-art open models built by Google DeepMind.
Note: this model requires Ollama 0.1.26 or later. Download it here.
https://ollama.com/download
Gemma is a new open model developed by Google and its DeepMind team. It’s inspired by Gemini models at Google.
Gemma is available in both 2b and 7b parameter sizes:
ollama run gemma:2b
ollama run gemma:7b (default)
The models undergo training on a diverse dataset of web documents to expose them to a wide range of linguistic styles, topics, and vocabularies. This includes code to learn syntax and patterns of programming languages, as well as mathematical text to grasp logical reasoning.
To ensure the safety of the model, the team employed various data cleaning and filtering techniques, including rigorous filtering for CSAM (child sexual abuse material), sensitive data filtering, and filtering based on content quality in compliance with Google’s policies.
Reference
Google Gemma:https://ai.google.dev/gemma/docs/model_card
latest
5.2GB • 430ed3535049 • 12 hours ago
ollama run gemma
2b
1.7GB • ff0200cc2d50 • 11 hours ago
ollama run gemma:2b
text
5.2GB • af57093b878e • 9 hours ago
ollama run gemma:text
instruct
5.2GB • 430ed3535049 • 12 hours ago
ollama run gemma:instruct
7b
5.2GB • 430ed3535049 • 12 hours ago
ollama run gemma:7b
2b-instruct
1.7GB • ff0200cc2d50 • 11 hours ago
ollama run gemma:2b-instruct
2b-text
1.7GB • 8e7dbe189b8c • 11 hours ago
ollama run gemma:2b-text
7b-instruct
5.2GB • 430ed3535049 • 12 hours ago
ollama run gemma:7b-instruct
7b-text
5.2GB • af57093b878e • 9 hours ago
ollama run gemma:7b-text
2b-instruct-q4_0
1.7GB • ff0200cc2d50 • 11 hours ago
ollama run gemma:2b-instruct-q4_0
2b-instruct-q4_1
1.8GB • 0531ce560c52 • 11 hours ago
ollama run gemma:2b-instruct-q4_1
2b-instruct-q5_0
1.9GB • bd0c49d488a7 • 11 hours ago
ollama run gemma:2b-instruct-q5_0
2b-instruct-q5_1
2.1GB • 8494d3a93bb0 • 11 hours ago
ollama run gemma:2b-instruct-q5_1
2b-instruct-q8_0
2.7GB • a1bea2062b57 • 11 hours ago
ollama run gemma:2b-instruct-q8_0
2b-instruct-q2_K
1.3GB • 4bd3d747b45a • 11 hours ago
ollama run gemma:2b-instruct-q2_K
2b-instruct-q3_K_S
1.4GB • e5ea800f0842 • 11 hours ago
ollama run gemma:2b-instruct-q3_K_S
2b-instruct-q3_K_M
1.5GB • 16b226fa6db2 • 11 hours ago
ollama run gemma:2b-instruct-q3_K_M
2b-instruct-q3_K_L
1.6GB • e79e55e83410 • 11 hours ago
ollama run gemma:2b-instruct-q3_K_L
2b-instruct-q4_K_S
1.7GB • 3cbacca7aba1 • 11 hours ago
ollama run gemma:2b-instruct-q4_K_S
2b-instruct-q4_K_M
1.8GB • 64a29cbcb55c • 11 hours ago
ollama run gemma:2b-instruct-q4_K_M
2b-instruct-q5_K_S
1.9GB • 08c46e51eec0 • 11 hours ago
ollama run gemma:2b-instruct-q5_K_S
2b-instruct-q5_K_M
2.0GB • 08e646708d53 • 11 hours ago
ollama run gemma:2b-instruct-q5_K_M
2b-instruct-q6_K
2.2GB • be48f404caec • 11 hours ago
ollama run gemma:2b-instruct-q6_K
2b-instruct-fp16
4.5GB • 4a53019167fe • 11 hours ago
ollama run gemma:2b-instruct-fp16
2b-text-q4_0
1.7GB • 8e7dbe189b8c • 11 hours ago
ollama run gemma:2b-text-q4_0
2b-text-q4_1
1.8GB • 0f5defc9d92c • 11 hours ago
ollama run gemma:2b-text-q4_1
2b-text-q5_0
1.9GB • ea2612176b5f • 11 hours ago
ollama run gemma:2b-text-q5_0
2b-text-q5_1
2.1GB • 8991086c344d • 11 hours ago
ollama run gemma:2b-text-q5_1
2b-text-q8_0
2.7GB • 5bffeae39c52 • 11 hours ago
ollama run gemma:2b-text-q8_0
2b-text-q2_K
1.3GB • 706d4ab3e4b9 • 11 hours ago
ollama run gemma:2b-text-q2_K
2b-text-q3_K_S
1.4GB • e20ed30a3bd0 • 11 hours ago
ollama run gemma:2b-text-q3_K_S
2b-text-q3_K_M
1.5GB • 2f3d7ff15ab1 • 11 hours ago
ollama run gemma:2b-text-q3_K_M
2b-text-q3_K_L
1.6GB • a6719f63fd68 • 11 hours ago
ollama run gemma:2b-text-q3_K_L
2b-text-q4_K_S
1.7GB • 979eec9c5947 • 11 hours ago
ollama run gemma:2b-text-q4_K_S
2b-text-q4_K_M
1.8GB • 42453f05d9d7 • 10 hours ago
ollama run gemma:2b-text-q4_K_M
2b-text-q5_K_S
1.9GB • 504bda6a88b7 • 10 hours ago
ollama run gemma:2b-text-q5_K_S
2b-text-q5_K_M
2.0GB • 5e528905a274 • 10 hours ago
ollama run gemma:2b-text-q5_K_M
2b-text-q6_K
2.2GB • 3c8c53aac289 • 10 hours ago
ollama run gemma:2b-text-q6_K
2b-text-fp16
4.5GB • 6ce2a676d014 • 11 hours ago
ollama run gemma:2b-text-fp16
7b-instruct-q4_0
5.2GB • 430ed3535049 • 12 hours ago
ollama run gemma:7b-instruct-q4_0
7b-instruct-q4_1
5.7GB • e1e4a2e0c8ee • 12 hours ago
ollama run gemma:7b-instruct-q4_1
7b-instruct-q5_0
6.2GB • de923fde2f26 • 12 hours ago
ollama run gemma:7b-instruct-q5_0
7b-instruct-q5_1
6.7GB • 2e51588baf45 • 12 hours ago
ollama run gemma:7b-instruct-q5_1
7b-instruct-q8_0
9.1GB • 61d0f0df3637 • 12 hours ago
ollama run gemma:7b-instruct-q8_0
7b-instruct-q2_K
3.7GB • 831e95226882 • 11 hours ago
ollama run gemma:7b-instruct-q2_K
7b-instruct-q3_K_S
4.2GB • e4aea70c287e • 11 hours ago
ollama run gemma:7b-instruct-q3_K_S
7b-instruct-q3_K_M
4.6GB • 92dd270cb673 • 11 hours ago
ollama run gemma:7b-instruct-q3_K_M
7b-instruct-q3_K_L
4.9GB • 1fa1f8e1a003 • 11 hours ago
ollama run gemma:7b-instruct-q3_K_L
7b-instruct-q4_K_S
5.2GB • bb7b8325814d • 11 hours ago
ollama run gemma:7b-instruct-q4_K_S
7b-instruct-q4_K_M
5.5GB • d9c26a968eb4 • 11 hours ago
ollama run gemma:7b-instruct-q4_K_M
7b-instruct-q5_K_S
6.2GB • 42630cbe71a2 • 11 hours ago
ollama run gemma:7b-instruct-q5_K_S
7b-instruct-q5_K_M
6.3GB • 556abeb39bfd • 11 hours ago
ollama run gemma:7b-instruct-q5_K_M
7b-instruct-q6_K
7.2GB • 5c7aded0b8bd • 11 hours ago
ollama run gemma:7b-instruct-q6_K
7b-instruct-fp16
17GB • f689ad351c8d • 11 hours ago
ollama run gemma:7b-instruct-fp16
7b-text-q4_0
5.2GB • af57093b878e • 9 hours ago
ollama run gemma:7b-text-q4_0
7b-text-q4_1
5.7GB • a7adb7322d8b • 9 hours ago
ollama run gemma:7b-text-q4_1
7b-text-q5_0
6.2GB • fd6dc849a9f8 • 9 hours ago
ollama run gemma:7b-text-q5_0
7b-text-q5_1
6.7GB • 938308342124 • 9 hours ago
ollama run gemma:7b-text-q5_1
7b-text-q8_0
9.1GB • 1b7b1e5e2f98 • 9 hours ago
ollama run gemma:7b-text-q8_0
7b-text-q2_K
3.7GB • e43e18a484ed • 9 hours ago
ollama run gemma:7b-text-q2_K
7b-text-q3_K_S
4.2GB • f40e21d459ff • 9 hours ago
ollama run gemma:7b-text-q3_K_S
7b-text-q3_K_M
4.6GB • ffd8ea66cf1f • 9 hours ago
ollama run gemma:7b-text-q3_K_M
7b-text-q3_K_L
4.9GB • 1676d1f86165 • 9 hours ago
ollama run gemma:7b-text-q3_K_L
7b-text-q4_K_S
5.2GB • 51854f1241b3 • 8 hours ago
ollama run gemma:7b-text-q4_K_S
7b-text-q4_K_M
5.5GB • 5ec372e05241 • 8 hours ago
ollama run gemma:7b-text-q4_K_M
7b-text-q5_K_S
6.2GB • df449b30e2e1 • 8 hours ago
ollama run gemma:7b-text-q5_K_S
7b-text-q5_K_M
6.3GB • dc8f812e49c7 • 8 hours ago
ollama run gemma:7b-text-q5_K_M
7b-text-q6_K
7.2GB • 9e7cfd3fab5b • 8 hours ago
ollama run gemma:7b-text-q6_K
7b-text-fp16
16GB • 1f1e9df10872 • 9 hours ago
ollama run gemma:7b-text-fp16
https://ollama.com/library/gemma/tags
Ollama
https://discord.gg/ollama
Get up and running with large language models locally.
macOS
Download
Windows preview
Download
Linux
curl -fsSL https://ollama.com/install.sh | sh
Manual install instructions
Docker
The official Ollama Docker image ollama/ollama is available on Docker Hub.
Libraries
- ollama-python
- ollama-js
Quickstart
To run and chat with Llama 2:
ollama run llama2
Model library
Ollama supports a list of models available on ollama.com/library
Here are some example models that can be downloaded:
Model Parameters Size Download Llama 2 7B 3.8GB ollama run llama2 Mistral 7B 4.1GB ollama run mistral Dolphin Phi 2.7B 1.6GB ollama run dolphin-phi Phi-2 2.7B 1.7GB ollama run phi Neural Chat 7B 4.1GB ollama run neural-chat Starling 7B 4.1GB ollama run starling-lm Code Llama 7B 3.8GB ollama run codellama Llama 2 Uncensored 7B 3.8GB ollama run llama2-uncensored Llama 2 13B 13B 7.3GB ollama run llama2:13b Llama 2 70B 70B 39GB ollama run llama2:70b Orca Mini 3B 1.9GB ollama run orca-mini Vicuna 7B 3.8GB ollama run vicuna LLaVA 7B 4.5GB ollama run llava Gemma 2B 1.4GB ollama run gemma:2b Gemma 7B 4.8GB ollama run gemma:7b Note: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Customize a model
Import from GGUF
Ollama supports importing GGUF models in the Modelfile:
-
Create a file named Modelfile, with a FROM instruction with the local filepath to the model you want to import.
FROM ./vicuna-33b.Q4_0.gguf
-
Create the model in Ollama
ollama create example -f Modelfile
-
Run the model
ollama run example
Import from PyTorch or Safetensors
See the guide on importing models for more information.
Customize a prompt
Models from the Ollama library can be customized with a prompt. For example, to customize the llama2 model:
ollama pull llama2
Create a Modelfile:
FROM llama2 # set the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 1 # set the system message SYSTEM """ You are Mario from Super Mario Bros. Answer as Mario, the assistant, only. """
Next, create and run the model:
ollama create mario -f ./Modelfile ollama run mario >>> hi Hello! It's your friend Mario.
For more examples, see the examples directory. For more information on working with a Modelfile, see the Modelfile documentation.
CLI Reference
Create a model
ollama create is used to create a model from a Modelfile.
ollama create mymodel -f ./Modelfile
Pull a model
ollama pull llama2
This command can also be used to update a local model. Only the diff will be pulled.
Remove a model
ollama rm llama2
Copy a model
ollama cp llama2 my-llama2
Multiline input
For multiline input, you can wrap text with """:
>>> """Hello, ... world! ... """ I'm a basic program that prints the famous "Hello, world!" message to the console.
Multimodal models
>>> What's in this image? /Users/jmorgan/Desktop/smile.png The image features a yellow smiley face, which is likely the central focus of the picture.
Pass in prompt as arguments
$ ollama run llama2 "Summarize this file: $(cat README.md)" Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.
List models on your computer
ollama list
Start Ollama
ollama serve is used when you want to start ollama without running the desktop application.
Building
Install cmake and go:
brew install cmake go
Then generate dependencies:
go generate ./...
Then build the binary:
go build .
More detailed instructions can be found in the developer guide
Running local builds
Next, start the server:
./ollama serve
Finally, in a separate shell, run a model:
./ollama run llama2
REST API
Ollama has a REST API for running and managing models.
Generate a response
curl http://localhost:11434/api/generate -d '{ "model": "llama2", "prompt":"Why is the sky blue?" }'Chat with a model
curl http://localhost:11434/api/chat -d '{ "model": "mistral", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }'See the API documentation for all endpoints.
Community Integrations
Web & Desktop
- Bionic GPT
- Enchanted (macOS native)
- HTML UI
- Chatbot UI
- Typescript UI
- Minimalistic React UI for Ollama Models
- Open WebUI
- Ollamac
- big-AGI
- Cheshire Cat assistant framework
- Amica
- chatd
- Ollama-SwiftUI
- MindMac
- NextJS Web Interface for Ollama
- Msty
Terminal
- oterm
- Ellama Emacs client
- Emacs client
- gen.nvim
- ollama.nvim
- ollama-chat.nvim
- ogpt.nvim
- gptel Emacs client
- Oatmeal
- cmdh
- tenere
- llm-ollama for Datasette’s LLM CLI.
- ShellOracle
Database
- MindsDB
Package managers
- Pacman
- Helm Chart
Libraries
- LangChain and LangChain.js with example
- LangChainGo with example
- LangChain4j with example
- LlamaIndex
- LangChain4j
- LiteLLM
- OllamaSharp for .NET
- Ollama for Ruby
- Ollama-rs for Rust
- Ollama4j for Java
- ModelFusion Typescript Library
- OllamaKit for Swift
- Ollama for Dart
- Ollama for Laravel
- LangChainDart
- Semantic Kernel - Python
- Haystack
- Elixir LangChain
- Ollama for R - rollama
- Ollama-ex for Elixir
- Ollama Connector for SAP ABAP
Mobile
- Enchanted
- Maid
Extensions & Plugins
- Raycast extension
- Discollama (Discord bot inside the Ollama discord channel)
- Continue
- Obsidian Ollama plugin
- Logseq Ollama plugin
- Dagger Chatbot
- Discord AI Bot
- Ollama Telegram Bot
- Hass Ollama Conversation
- Rivet plugin
- Llama Coder (Copilot alternative using Ollama)
- Obsidian BMO Chatbot plugin
- Copilot for Obsidian plugin
- Obsidian Local GPT plugin
- Open Interpreter
- twinny (Copilot and Copilot chat alternative using Ollama)
- Wingman-AI (Copilot code and chat alternative using Ollama and HuggingFace)
- Page Assist (Chrome Extension)
参考资料:
https://github.com/ollama/ollama
- MindsDB
-
")
")
")
")
还没有评论,来说两句吧...